

Auch ich war oft unzufrieden mit meinem Audio…hier die Lösung!!!
-ohne Budgetprobleme.
Wir nutzen Windows 11, OBS , Fairlight in Davinci Resolve Studio (sollte alles auch mit der gratis Version klappen)
USB-Mikrofone werden oft unterschätzt. Mit dem Yeti GX oder einem anderen Mikrofon bekommst du bei korrektem Setup saubere Rohaufnahmen und kannst sie in DaVinci Resolve/Fairlight auf „YouTube-/Podcast-Qualität“ bringen – ohne Audio-Interface, ohne XLR-Kette. Entscheidend sind Abtastrate, Pegel, verlustfreie Aufnahme und eine saubere Dynamik-/EQ-Bearbeitung.
Beginnen wir mit dem Endprodukt. Wahrnehmung ist mehr als technische Datenanalyse.- weniger Rauschen und mehr Sprachdetails.
DEINE NAVIGATION
- 0.1 Auswertung
- 0.2 Schnellfazit
- 0.3 Hörtest: So kann jeder Leser sauber A/B vergleichen (ohne sich vom Pegel täuschen zu lassen)
- 0.4 Technische Vergleichsdaten (Container/Codec)
- 0.5 Messwerte: Audioqualität im Detail
- 0.6 Warum die Windows-Aufnahme oft schlechter wird (typische Ursachen)
- 0.7 Ergebnis: Welche Datei „gewinnt“?
- 0.8 Was du brauchst
- 1 Schritt 1: Windows 11 – USB Mikrofon korrekt als Eingabe einrichten
- 2 Schritt 2: OBS Studio – nur Audio aufnehmen, verlustfrei speichern
- 3 Schritt 3: Ultimative Anleitung
- 3.1 3.1 Dynamik-Panel: optimierte Werte
- 3.2 3.2 EQ (Channel EQ) – Sprachklarheit
- 3.3 Band 1 (Highpass)
- 3.4 Band 2 – Bereichstaste L
- 3.5 Band 3 – Bereichstaste ML
- 3.6 Band 4 – Bereichstaste MH
- 3.7 Band 5 – Bereichstaste H
- 3.8 Band 6 (Lowpass, optional)
- 3.9 Konkret in deinem Fairlight-EQ
- 3.10 Bedeutung der Bereichstasten
- 3.11 Beispiel:
- 3.12 Merksatz
- 3.13 Wichtig
- 3.14 3.3 Export-Empfehlung
- 3.15 ❗ Was hier nicht dabei ist
- 4 Häufige Probleme und schnelle Lösungen
Hörtest (A) in folgendem Video: bearbeitet Ergebnis. OBS/Fairlight
Hörtest (B) in folgendem Video: mit Windows und USB Mikrofon
Wenn Du sofort lostlegen möchtest:
Zur ultimativen Schnellanleitung
Auswertung
Windows-Aufnahme vs. OBS/Fairlight
Welche Version hat die bessere Audioqualität?
In diesem Vergleich stelle ich zwei Dateien gegenüber:
- A: Hörtest: OSB und Fairlight (Klarer Gewinner)
- B:Hörtest: windows Audiorecorder.
Wichtig: Der Vergleich basiert nicht auf subjektivem Hören, sondern auf signalbasierten Messwerten (Lautheit, Peaks, Rauschboden, Höhenanteil). Der Leser soll zusätzlich selbst hören – darum sind unten konkrete Schritte für einen fairen A/B-Hörtest.
Wenn ich nicht alles bauf die Spitze treiben möchte spare ich mir Arbeit und nutze nur OSB .
Bernd Bischof
Schnellfazit
Die höhere Audioqualität hat Datei A (Gratis ANleitung.mov).
Grund: deutlich weniger Grundrauschen, besseres Signal-Rausch-Verhältnis und mehr Sprachpräsenz. Datei B ist zwar etwas lauter, aber hörbar „schmutziger“ und tendenziell dumpfer.
Hörtest: So kann jeder Leser sauber A/B vergleichen (ohne sich vom Pegel täuschen zu lassen)
Der häufigste Fehler beim Vergleichen: Die lautere Datei wirkt „besser“, obwohl sie nur lauter ist. So geht es korrekt:
- Beide Dateien direkt auf der Website einbetten (zwei Player untereinander).
- Die gleichen 10–20 Sekunden auswählen (z. B. eine Passage mit S-Lauten + normaler Sprache).
- Pegel angleichen (Level-Matching):
- Ziel: Beide Clips sollen gleich laut wirken.
- Praktisch: Im Editor oder Player die lautere Datei um ca. 1 dB absenken (bei mir war B ~1.2 LUFS lauter).
- Mit Kopfhörer hören, dann mit Lautsprechern.
- Achte auf:
- Rauschen in Sprechpausen
- Zischlaute (S/Sch): klar oder kratzig?
- Nähe/Präsenz: klingt die Stimme „vorne“ oder „hinter einem Vorhang“?
- Atem/Room Tone: ruhig oder „fizzelig“/schwirrend?
Technische Vergleichsdaten (Container/Codec)
Beide Dateien sind technisch nahezu gleich kodiert:
- MOV, Video: H.264, 3840×2160, 24 fps
- Audio: AAC, 48 kHz, Stereo, 320 kbit/s
- Dauer: 50.625 s
Das ist wichtig: Der Codec ist nicht der Hauptgrund für den Qualitätsunterschied – der liegt sehr wahrscheinlich in der Aufnahme-/Signalstrecke (Windows-Audiopfad, AGC, Rauschunterdrückung, Treiber, falsche Eingangspegel, doppelte Verarbeitung).
Messwerte: Audioqualität im Detail
| Messwert | Fairlight OSB (A) | Windows (B) | Bedeutung |
|---|---|---|---|
| Integrated Loudness (LUFS) | -28.9 | -27.7 | B ist ~1.2 LUFS lauter |
| True Peak (dBFS) | -12.4 | -8.6 | B hat ~3.8 dB höhere Spitzen |
| Noise-Floor (dBFS, Schätzung) | -70.7 | -60.1 | B hat ~10.6 dB mehr Grundrauschen |
| SNR-Schätzung | 42.8 dB | 33.1 dB | B ist ~9.7 dB schlechter |
| HF-Anteil >6 kHz | 3.29% | 0.69% | B hat deutlich weniger Höhen (dumpfer) |
| Clipping | 0% | 0% | kein digitales Clipping |
Was heißt das in normaler Sprache?
- Noise-Floor/Rauschboden: wie „laut“ das Grundrauschen ist, wenn niemand spricht. 10 dB Unterschied ist groß – das hört man fast immer.
- SNR (Signal-Rausch-Verhältnis): je höher, desto sauberer wirkt Sprache.
- HF-Anteil/Höhen: weniger Höhen kann „wärmer“ sein – oft ist es aber ein Zeichen für zu aggressive Rauschunterdrückung oder falsche Windows-/Treiber-Filter.
Warum die Windows-Aufnahme oft schlechter wird (typische Ursachen)
Wenn Windows/OBS/Tooling „hilft“, verschlechtert es Sprache häufig:
- Automatische Verstärkung (AGC) pumpt leise Stellen hoch → mehr Rauschen.
- Rauschunterdrückung entfernt nicht nur Rauschen, sondern auch Sprachdetails → „dumpf“, „wattig“.
- Doppelte Verarbeitung (z. B. Windows Enhancements + OBS Filter + Editor) → Artefakte, Phasenprobleme.
- Falscher Eingangspegel: zu leise aufgenommen → später hochgezogen → Rauschen steigt.
- Stereo statt Mono bei einem Mono-Mikro/Signal → unnötige Nebenwirkungen (Phasen-/Raumanteil).
Ergebnis: Welche Datei „gewinnt“?
Gewinner Audioqualität:
Hörtest A: bearbeitet Ergebnis. OBS/Fairlight.
Objektiv messbar: wesentlich geringerer Rauschboden und bessere Sprachdetails.
Datei B ist zwar etwas lauter, aber Pegel ist kein Qualitätsmerkmal – den kann man jederzeit anpassen.
Was du brauchst
- Yeti GX (oder anders usb Microfon)
- Windows 11
- OBS Studio
- DaVinci Resolve (Fairlight)
- Kopfhörer zum Kontrollhören (waere von Vorteil)
Schritt 1: Windows 11 – USB Mikrofon korrekt als Eingabe einrichten
am Beispiel Yeti GX (einma video, einmal Text)
1.2 Klassische Sound-Systemsteuerung öffnen (für „Erweitert“)
Windows: Weitere Soundeinstellungen → Aufnahme → Mikrofon (Yeti GX) → Eigenschaften → Erweitert
- Standardformat: 1 Kanal, 24 Bit, 48000 Hz
- Exklusiver Modus:
- Anwendungen haben alleinige Kontrolle → AN
- Anwendungen im exklusiven Modus haben Priorität → AN
1.3 Pegel in Windows setzen
Reiter Pegel: Startwert ~78% (bei mir bewährt).
Regel: Lieber etwas niedriger als Verzerrung riskieren.
Schritt 2: OBS Studio – nur Audio aufnehmen, verlustfrei speichern
2.1 Audio-Geräte in OBS aufräumen
OBS: Einstellungen → Audio
- Desktop-Audio: Deaktiviert
- Mikrofon/Aux: Deaktiviert
- Nur über Quelle in der Szene aufnehmen (siehe 2.2)
Warum: Verhindert doppelte Mikro-Signale und Chaos im Mixer.
2.2 Audioquelle hinzufügen (Yeti GX)
In deiner Szene: Quellen → + → Audioeingabeaufnahme → Neu erstellen → Gerät: „Mikrofon (Yeti GX)“
2.3 Aufnahmeformat und Codec: MKV + PCM 24 Bit
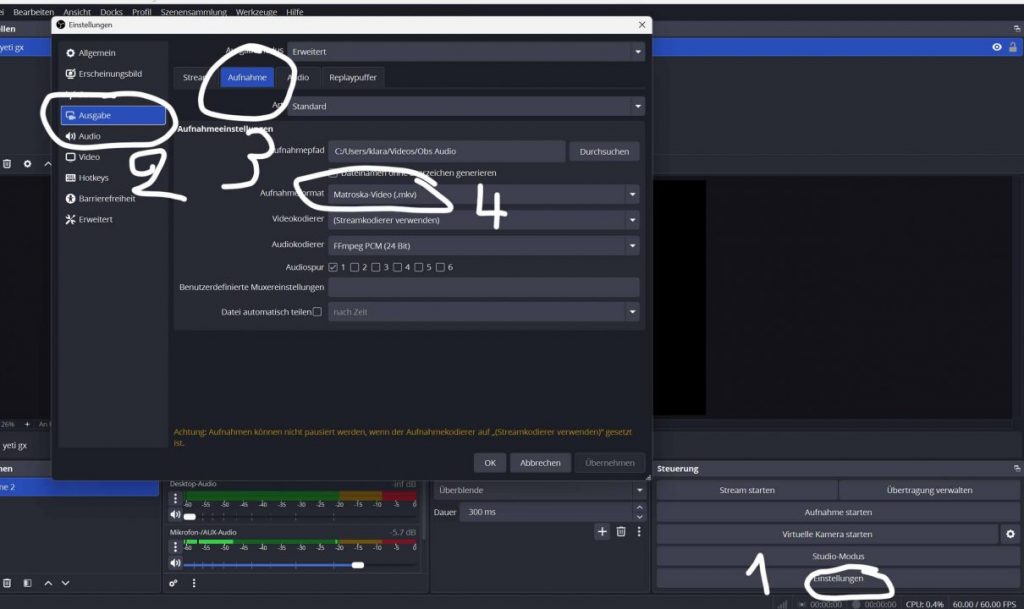
OBS: Einstellungen → Ausgabe → Ausgabemodus: Erweitert → Aufnahme
- Aufnahmeformat: Matroska (.mkv)
- Audiokodierer: FFmpeg PCM (24 Bit)
- Audiospur: 1
2.4 Gelbe Meldung „keine Videoquellen“
Wenn OBS warnt: „Keine Videoquellen, leerer Bildschirm“ → Ja klicken.
Für reine Audioaufnahme ist das korrekt.
Fals Du nichts hörst:
2.5 Monitoring: Warum du Pegel siehst, aber nichts hörst
Du hörst nur dann live, wenn Audiomonitoring aktiv ist.
OBS: Audiomixer → Zahnrad → Erweiterte Audioeigenschaften
- yeti gx: „Monitoring und Ausgabe“ (wenn du dich live hören willst)
- Desktop-Audio: Monitoring aus
- Mikrofon/AUX: entfernen oder deaktivieren
Hinweis: Für reine Aufnahme ist Monitoring optional. Für Kontrolle ist es praktisch.
2.6 Speicherort der Aufnahmen
damit du Sie sofort wiederfindest. Leg Dir einen eigenen Ordner an. Das erspart viel Sucherei.
OBS: Datei → Aufnahmen anzeigen
oder Einstellungen → Ausgabe → Aufnahme → Aufnahmepfad
Beispiel: C:\Users\klara\Videos\Obs Audio
Schritt 3: Ultimative Anleitung
DaVinci Resolve / Fairlight – Die Mühe lohnt sich.
Schau das Video zur Orientierung, dann trage die Daten ein wie unten angegenben fertig.
Unser Ziel:
klare Sprache, kontrollierte Dynamik, keine Peaks, weniger Rauschen.
3.1 Dynamik-Panel: optimierte Werte
Expander (sanft)
- Threshold: –40.0 dB
- Bereich: 12.0 dB
- Ratio: 1:1.3
- Attack: 2.0 ms
- Hold: 0.00 ms
- Release: 150 ms
Kompressor (Sprache)
- Threshold: –18.0 dB
- Ratio: 3.0:1
- Knee: 15
- Mischen: 0
- Attack: 10.0 ms
- Hold: 0.00 ms
- Release: 120 ms
Limiter (Sicherheit)
- Threshold: –1.0 dB
- Attack: 1.0 ms
- Hold: 0.00 ms
- Release: 100 ms
Make-Up Gain
- +3.0 dB (als Startwert)
3.2 EQ (Channel EQ) – Sprachklarheit
Starte hiermit:
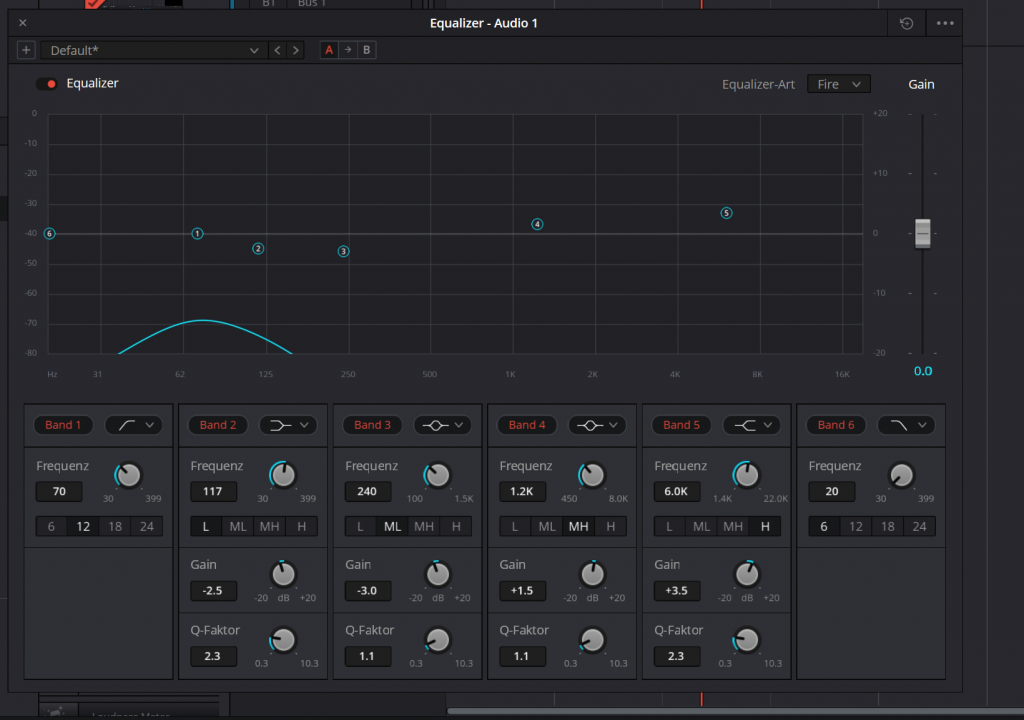
Band 1 (Highpass)
Typ: Highpass
Frequenz: 70 Hz
Steilheit: 12 dB/Okt
Warum so:
- 70 Hz entfernt Trittschall, Tisch-/Armbewegungen, Körperschall, Verkehr/Brummen und den „Sub“-Müll, der für Sprachverständlichkeit nichts bringt, aber den Kompressor/Limiter unnötig arbeiten lässt.
- 12 dB/Okt ist eine moderate Steilheit: genug, um Rumpeln sauber zu reduzieren, ohne die Stimme „abzuschneiden“ oder unnatürlich dünn zu machen (steilere Filter klingen schneller „hart“).
- Ergebnis: mehr Headroom, weniger „Wummern“, stabilere Dynamikbearbeitung danach.
Band 2 – Bereichstaste L
Bereich: L
Frequenz: 117 Hz
Gain: –2.5 dB
Q: 2.3
Warum so:
- 117 Hz liegt typischerweise im Boom-/Körperbereich vieler Stimmen (bei Nahbesprechung/Proximity-Effekt besonders). Genau dort sammelt sich oft das „Bauchige“, das Sprache größer, aber auch unklarer macht.
- –2.5 dB ist bewusst kein radikaler Schnitt: Es reduziert den Boom, lässt aber noch Wärme stehen.
- Q 2.3 ist relativ schmal: Du greifst gezielt die „Problem-Resonanz“ an, statt den ganzen Bassbereich auszudünnen.
- Ergebnis: weniger „Wummern“, klarere Silben, weniger „Pumpeffekt“ im Kompressor.
Band 3 – Bereichstaste ML
Bereich: ML
Frequenz: 240 Hz
Gain: –3.0 dB
Q: 1.1
Warum so:
- 240 Hz ist ein Klassiker für „Mumpf“/„Boxiness“ (das „Karton“-Gefühl). Dieser Bereich überlagert Konsonanten und macht Stimme matt.
- –3.0 dB ist ein deutlicher, aber noch normaler Korrekturschnitt: oft reicht genau das, um aus „muffig“ → „aufgeräumt“ zu kommen.
- Q 1.1 ist breiter als Band 2: Mumpf ist selten eine einzige Resonanz, sondern eher ein Bereich. Breiter arbeiten klingt natürlicher.
- Ergebnis: mehr Transparenz, weniger „Kiste“, die Stimme setzt sich besser durch.
Band 4 – Bereichstaste MH
Bereich: MH
Frequenz: 1.2 kHz
Gain: +1.5 dB
Q: 1.1
Warum so:
- 1.2 kHz liegt im Bereich von Präsenz/Sprach-Nasalität. Kleine Anhebung kann die Stimme nach vorne holen, ohne schon in „S“-Schärfe (5–8 kHz) zu landen.
- +1.5 dB ist bewusst subtil: Es verbessert Verständlichkeit, ohne „telefonig“ oder nasal zu werden.
- Q 1.1 wieder eher breit, damit die Präsenz natürlich ansteigt und nicht wie ein „Peak“ klingt.
- Ergebnis: mehr Durchsetzung, bessere Wortkonturen bei normaler Lautstärke.
Band 5 – Bereichstaste H
Bereich: H
Frequenz: 6.0 kHz
Gain: +2.0 dB
Q: 2.3
Warum so:
- 6 kHz ist der Bereich, der Sprache „klar/knackig“ macht: Zischnahe Details, Artikulation, „Air“-Anmutung (ohne gleich reines „S“-Zischen bei 7–9 kHz voll zu treffen).
- +2.0 dB ist eine typische „Clarity“-Anhebung für YouTube/Online, damit die Stimme auch auf Handy-Lautsprechern verständlich bleibt.
- Q 2.3 relativ schmal, weil in diesem Bereich schnell Härte entsteht. Schmaler bedeutet: du gibst „Glanz“ gezielt, ohne den ganzen Höhenbereich hochzuziehen (was Rauschen, Raum und Zischeln verstärken würde).
- Ergebnis: mehr Definition, bessere Verständlichkeit auf kleinen Speakern, ohne alles „scharf“ zu machen.
Band 6 (Lowpass, optional)
Typ: High self
Frequenz: 18 kHz
Steilheit: 12 dB/Okt
Warum so:
- Oberhalb von ~18 kHz steckt bei Sprachaufnahmen meist kein Nutzsignal für Verständlichkeit, aber oft Rauschen, digitales Zirpen, Luft/Elektronik-Hiss.
- 18 kHz statt 22 kHz: 22 kHz ist so hoch, dass es häufig kaum wirkt (je nach Samplerate/Material) – 18 kHz ist ein praktischer Cut, der Störanteile spürbarer reduziert, ohne die „Luftigkeit“ komplett zu töten.
- 12 dB/Okt wieder moderat: du reduzierst „ultra-high“-Müll, ohne einen hörbaren „Deckel“ auf die Höhen zu setzen.
- Ergebnis: weniger Hiss/Ultrahöhen-Artefakte, sauberere Stimme nach Kompressor/Limiter.
Wichtige Kontrolle (damit es wirklich passt)
- Wenn die Stimme nach Band 1 zu dünn wird: Highpass auf 60 Hz senken oder Steilheit prüfen.
- Wenn nach Band 2/3 die Stimme zu „klein“ wirkt: Band-2 Cut auf –1.5 dB reduzieren oder Band-3 Cut auf –2 dB.
- Wenn Band 5 „spitz“ wird (S-Laute unangenehm): Gain auf +1 dB oder Frequenz leicht verschieben (z. B. 5.2–6.5 kHz). In harten Fällen zusätzlich De-Esser statt weiter EQ-Boost.
Kurzfassung:
„Bereichstaste setzen“ heißt: du wählst, in welchem Frequenzbereich der Frequenz-Regler dieses Bandes arbeiten darf.
Das ist keine Klangänderung, sondern eine Voreinstellung für den Reglerbereich.
Konkret in deinem Fairlight-EQ
Unter Band 2, 3, 4 und 5 siehst du vier kleine Tasten:
L | ML | MH | H
Diese Tasten bestimmen den Arbeitsbereich des Frequenz-Knopfes.
Was passiert technisch?
- Der Frequenz-Regler hat unterschiedliche Min/Max-Werte, je nachdem welche Taste aktiv ist.
- So kannst du präzise einstellen, ohne versehentlich im falschen Bereich zu landen.
Bedeutung der Bereichstasten
| Taste | Bedeutung | Typischer Bereich |
|---|---|---|
| L | Low | ca. 30–200 Hz |
| ML | Mid-Low | ca. 100–600 Hz |
| MH | Mid-High | ca. 500 Hz – 3 kHz |
| H | High | ca. 2 kHz – 8 kHz+ |
Beispiel:
Band 4
- Frequenz: 1.2 kHz
- Ohne Bereichstaste:
Der Regler wäre ungenau, schwer fein einzustellen.- Mit Bereichstaste
MH:
Der Regler arbeitet genau im passenden Mittenbereich → saubere Einstellung.- „Bereichstaste setzen“ = vor dem Drehen des Frequenz-Knopfs die passende Taste anklicken.
Merksatz
Erst Bereich wählen (L / ML / MH / H), dann Frequenz einstellen.
Wichtig
- Bereichstasten ändern nicht den Klang
- Sie verhindern Fehlbedienung
- Profis nutzen sie immer zuerst
Wenn du willst, machen wir als Nächstes eine Mini-Checkliste: „Welche Bereichstaste bei welchem Klangproblem“ (z. B. dumpf, nasal, zischend).
3.3 Export-Empfehlung
- Master: WAV 24 Bit / 48 kHz
- Für maximale Kompatibilität zusätzlich: WAV 16 Bit / 48 kHz
- Ziel-Lautheit (typisch Online): –16 LUFS integrated (falls du Loudness normalisierst)
Bedeutung der Symbole in Fairlight/Davinci Resolve (Filtertypen)

1️⃣ Oberstes Symbol
High-Cut (Low-Pass)
- Bedeutung: Schneidet hohe Frequenzen ab
- Einsatz: Zischeln, harte Höhen, digitales „Fiepen“ dämpfen
- Sprache: Nur vorsichtig verwenden
- Merksatz: Alles OBERHALB der Frequenz wird leiser
2️⃣ Zweites Symbol
High-Shelf
- Bedeutung: Hebt oder senkt alle hohen Frequenzen ab der Frequenz
- Einsatz: „Luft“, Brillanz, Frische
- Sprache: +1 bis +3 dB für Klarheit
- Merksatz: Höhen-Regler ab einem Punkt
3️⃣ Drittes Symbol (mit Kreis in der Mitte)
Bell (Peak / Glocke)
- Bedeutung: Bearbeitet einen gezielten Frequenzbereich
- Einsatz:
- Nasalität (300–800 Hz)
- Präsenz (2–4 kHz)
- Zischlaute (5–8 kHz)
- Wichtigster Filter für Sprache
- Merksatz: Chirurgischer Eingriff
4️⃣ Unterstes Symbol
Low-Shelf
- Bedeutung: Hebt oder senkt alle tiefen Frequenzen unterhalb der Frequenz
- Einsatz:
- Stimme voller machen
- Bass kontrollieren
- Sprache: Oft leicht absenken, wenn es dröhnt
- Merksatz: Bass-Regler bis zu einem Punkt
❗ Was hier nicht dabei ist
Der Low-Cut (High-Pass) ist ein eigenes Band (meist Band 1)
→ Symbol sieht aus wie eine ansteigende Kurve von links nach rechts.
Häufige Probleme und schnelle Lösungen
„Ich sehe Pegel, höre aber nichts“
- OBS Monitoring steht auf „Monitoring aus“ → auf „Monitoring und Ausgabe“ setzen.
- Windows-Ausgabegerät falsch (HDMI/Monitor) → Soundausgabe auf Kopfhörer/Lautsprecher stellen.
„Windows Audiorecorder spielt meine OBS-Datei nicht ab“
- OBS nimmt als MKV + PCM 24 Bit auf. Windows-Audiorecorder kann das nicht.
- Abspielen mit VLC oder direkt in DaVinci Resolve importieren.
„Ton verzerrt / kratzt“
- Windows-Mikrofonpegel zu hoch → von 78% Richtung 70% senken.
- In OBS Peaks dauerhaft nahe 0 dB → Pegel runter, nicht „nachträglich reparieren“.
FAQ
Ist ein USB-Mikro wie das Yeti GX „professionell genug“?
Ja, wenn du sauber pegelst und verlustfrei aufnimmst. Die meisten Qualitätsprobleme kommen von falschen Einstellungen, Raum und Nachbearbeitung.
Warum MKV und nicht MP4?
MKV ist crash-sicher. Bei MP4 kann die Datei bei Absturz unbrauchbar werden.
Warum PCM 24 Bit?
Verlustfrei und ideal für Bearbeitung in Fairlight. AAC/Opus sind komprimiert.
Schreibe einen Kommentar